SELECT table1.column, table2.column
FROM table1, table2
WHERE table1.column1 = table2.column;
1. CARTESIAN PRODUCT
- 조인 조건이 생략된 경우
- 조인 조건이 잘못된 경우
- 첫 번째 테이블의 모든 행이 두 번째 테이블의 모든 행과 조인되는 경우
SELECT table1.col, table2.col
FROM table1, table2;
--카티션프로덕트발생(조인 조건이 없기 때문)
2. EQUI JOIN
- 2개 이상의 테이블이 공통된 열에 의해 논리적 결합하는 조인 기법
- WHERE 절에 사용된 열들이 동등연산자(=) 에 의해 비교
select e.first_name, e.department_id, d.department_name
from employees e, departments d
where e.department_id = d.department_id;
3. SELF JOIN
- 자체적 테이블 조인
select e.first_name, m.first_name
from employees e, employees m
where e.manager_id = m. employee_id and e.employee_id=103;
4. NON-EQUI JOIN
- equal 연산자(=)로 조인하지 않음
select e.first_name, e.salary, j.job_title
from employees e, jobs j
where e.salary
between j.min_salary and j.max_salary
order by e.first_name;
5. OUTER JOIN
- 조인 조건을 만족하지 않는 행들도 보기 위해서 Outer 조인을 사용함
- Outer 조인 연산자는 더하기 기호(+) 임.
SELECT table.column, table.column
FROM table1, table2
WHERE table1.column(+) = table2.column;
SELECT table.column, table.column
FROM table1, table2
WHERE table1.column = table2.column(+);
select e.employee_id, e.first_name, e.hire_date,
j.start_date, j.end_date, j.job_id, j.department_id
from employees e, job_history j
where e.employee_id = j.employee_id
order by j.employee_id;
안시 조인
- 오라클 9i 버전부터 ANSI SQL 표준 문법 사용이 가능
- 조인의 형태가 FROM절에서 지정되며, 조인 조건이 ON 절 또는 USING 절에 표시
SELECT t1.col, t2, col
FROM t1
[LEFT|RIGHT|FULL][OUTER] JOIN t2
ON jooin_conditions
[WHERE conditions];
1. CROSS JOIN
- 두 개의 테이블에 대한 Cartesian Product와 같은 결과 출력
SELECT table1.column1, table2.column2
FROM table1
CROSS JOIN table2;
select employee_id, department_name
from employees
cross join departments;
2. NATURAL JOIN
- 모든 같은 이름을 갖는 열들에 대해 조인
- 지정해주지 않아도 자동으로 같은 이름가진 열에 대해 Equi조인을 수행한다.
SELECT table1.column1, table2.column2
FROM table1
NATURAL JOIN talbe2;
select first_name, job_title
from employees
natural join jobs;
3. USING JOIN
- using 절을 이용하여 원하는 열에 대해서만 선택적으로 Equi 조인을 할 수 있음.
SELET table1.column1, table2.column2
FROM table1
JOIN table2
USING (column);
select first_name, department_name
from employees
join departments
using (department_id);
4. ON JOIN
- on을 이용해 where에 들어갈 조인 조건을 적을 수 있음
SELECT table1.column1, table2.column2
FROM table1
JOIN table2
ON join_condition;
select department_name, street_Address, city, state_province
from departments d
join locations l
on d.location_id = l.location_id;
1) 여러 테이블의 조인
select e.first_name, d.department_name,
l.street_address || ', ' || l.city || ', '||
l.state_province as address
from employees e
join departments d on e.department_id = d.department_id
join locations l on d.location_id = l.location_id;
2) WHERE 절과의 혼용
select e.first_name as name,
d.department_name as department
from employees e
join departments d
on e.department_id = d.department_id
where employee_id = 103;
select e.first_name, d.department_name,
l.street_address || ', ' || l.city || ', '||
l.state_province as address
from employees e
join departments d on e.department_id = d.department_id
join locations l on d.location_id = l.location_id
where employee_id=103;
3) ON절에 WHERE절의 조건 추가
select e.first_name as name,
d.department_name as department
from employees e
join departments d
on e.department_id = d.department_id and employee_id = 103;
select e.first_name, d.department_name,
l.street_address || ', ' || l.city || ', '||
l.state_province as address
from employees e
join departments d on e.department_id = d.department_id
join locations l on d.location_id = l.location_id and employee_id=103;
5. OUTER JOIN
SELECT table1.column, table2.column
FROM table1
[LEFT|RIGHT|FULL][OUTER]JOIN table2
ON join_conditions
select e.employee_id, e.first_name, e.hire_date,
j.start_date, j.end_date, j.job_id, j.department_id
from employees e
left outer join job_history j
on e.employee_id = j.employee_id
order by e.employee_id;
1) LEFT OUTER JOIN
- 왼쪽의 테이블이 기준
select department_name, first_name
from departments d
left join employees e
on d.manager_id = e.employee_id;
2) RIGHT OUTER JOIN
- 오른쪽 테이블이 기준
select department_name, first_name
from employees e
right join departments d
on d.manager_id = e.employee_id;
Anlytic_Funtion
OVER ( PARTITION BY column_list
ORDER BY column_list [ASC|DESC]
Windowing)
* PARTITION BY : 열의 행을 그룹화. 분석 함수로 계산될 대상 행의 그룹을 지정.
* ORDER BY : 정렬 (가장 많이 사용). 파티션 안에서의 순서를 지정.
* Windowing : 윈도우 절. 파티션으로 분할 그룹화 된 그룹에 대해 더 상세한 그룹으로 분할 할 때 사용
1. 순위 구하기 함수 - RANK, DENSE_RANK, ROW_NUMBER
RNAK
순위 결정(중복순위 계산o) 같은 값이면 1,2,2,4위 순
DENSE_RANK
순위 결정(중복순위 계산x) 같은 값이면 1,2,2,3,4위 순
ROW_NUMBER
조건을 만족하는 모든 행의 번호를 제공 - select절에서 순서를 매기기 때문에 - order by로 정렬을 하면 순서가 바뀔 수 잇음 - DB에 데이터가 물리적으로 저장된 순서에 따라 다름.
select employee_id, department_id, salary,
rank() over(order by salary desc) sal_rank,
dense_rank() over(order by salary desc) sal_dense_rank,
row_number() over(order by salary desc) sal_number
from employees;
2. 가상순위와 분포 - CUME_DIST, PERCENT_RANK
CUME_DIST
최대값 1을 기준으로 분산된 값 제공. 첫번째 0이 아님.
PERCENT_RANK
최대값 1을 기준으로 백분율 값 제공. 첫번째는 0
select employee_id, department_id,salary,
cume_dist() over(order by salary desc) sal_cume_dist,
percent_rank() over(order by salary desc) sal_pct_rank
from employees;
3. 비율 함수 - RATIO_TO_REPORT
RATIO_TO_REPORT
해당 컬럼 값의 총 값 중 차지하는 비율을 백분율로 표현. 소수점으로 제공
select first_name, salary,
round(ratio_to_report(salary) over(), 4) as salary_ratio
from employees
where job_id ='IT_PROG';
4. 분배 함수 - NTILE
NTILE
전체 데이터의 분포를 n개의 구간으로 나누어 표시 만약 45명을 10개씩 나누면 4.5이므로 앞쪽부터 하나씩 더 가져감
select employee_id, department_id, salary,
ntile(10) over(order by salary desc) sal_quart_tile
from employees
where department_id='50';
5. LAG, LEAD
- 윈도우 구간 지정
LAG
윈도우의 이전 n번째 행의 값을 가져옴 LAG(salary,2,0) : salary에서 현재 행 이전 2번째 행의 값을 가져오고 값이 없으면 0 출력.
LEAD
윈도우의 이후 n번째 행의 값을 가져올 수 있음 - LEAD(hire_date, 1,0) : 현재 행 기준 다음 입사일 값을 가져오고 없으면 0 출력
select employee_id,
lag(salary,1,0) over(order by salary) as lower_sal,
salary,
lead(salary,1,0) over(order by salary) as higher_sal
from employees
order by salary;
6. LISTAGG
LISTAGG(expression, 'delimiter')
WITHIN GROUP(ORDER BY column)
LISTAGG
함수의 expression을 delimiter로 연결해 여러 행을 하나의 행으로 변환해 출력하는 함수
select department_id, first_name
from employees
group by department_id;
--에러
select department_id,
listagg(first_name,', ') within group(order by hire_date)
from employees
group by department_id;
윈도우 절
- 파티션으로 분할된 그룹에 대해 다시 그룹을 만드는 역할
{rows|range}
{BETWEEN {
UNBOUNDED PRECEDING
| CURRENT ROW
| value_expr{PRECEDING|FOLLOWING}
}
AND {
UNBOUNDED FOLLOWING
| CURRENT ROW
| value_expr{PRECEDING|FOLLOWING}
}
|{UNBOUNDED PRECEDING
| CURRENT ROW
| value_Expr PRECEDING
}
}
select department_id, first_name, salary,
sum(salary) over(partition by department_id
order by salary
rows between unbounded preceding
and current row) as sum_rows
from employees;
select department_id, first_name, salary,
sum(salary) over(partition by department_id
order by salary
range between unbounded preceding
and current row) as sum_rows
from employees;
select avg(salary), regr_avgx(commission_pct, salary), regr_avgy(commission_pct, salary)
from employees;
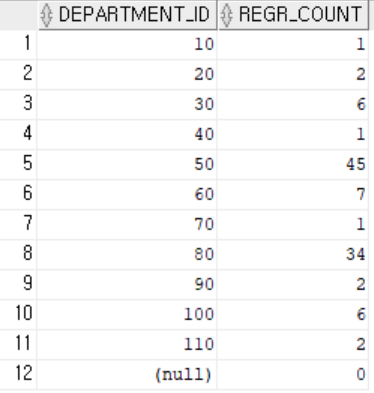
2. REGR_COUNT(y,x)
- 두 인수의 값이 not null인 쌍 수를 계산
select distinct department_id,
regr_count(manager_id, department_id)
over (partition by department_id) "REGR_COUNT"
from employees
order by department_id;
3. REGR_SLOPE(y,x), REGR_INTERCEPT(y,x)
* slope: 회귀 직선의 기울기 측정(weight)
- COVAR_POP(y,x) / VAR_POP(x)
*intercept : 회귀 직선의 y절편(bias)
- AVG(y) - REGR_SLOPE(y,x) * AVG(x)
select
job_id, employee_id, salary,
round(sysdate-hire_date) "working_day",
round(regr_slope(salary, sysdate-hire_date)
over(partition by job_id),2) "regr_slope",
round(regr_intercept(salary, sysdate-hire_date)
over(partition by job_id),2) "regr_intercept"
from employees
where department_id = 80
order by job_id, employee_id;
select
distinct
job_id,
round(regr_slope(salary, sysdate-hire_date)
over(partition by job_id),2) "regr_slope",
round(regr_intercept(salary, sysdate-hire_date)
over(partition by job_id),2) "regr_intercept",
round(regr_r2(salary, sysdate-hire_date)
over(partition by job_id),2) "regr_r2"
from employees
where department_id=80;
=> 두 회귀모형 중 SA_MAN이 SA_REP보다 유용성이 더 높다고 판단할 수 있다.
피벗 테이블
1. 관계형 데이터베이스 형식과 스프레드시트 형식
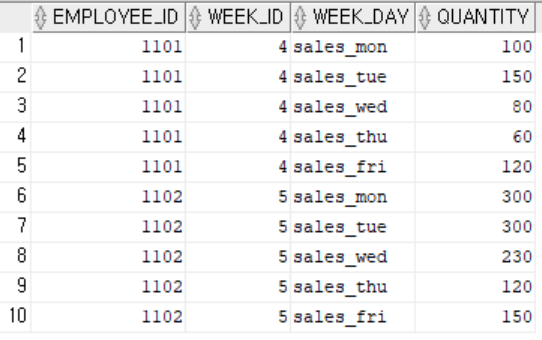
create table sale_log(
employee_id number(6),
week_id number(2),
week_day varchar(10),
quantity number(8,2)
);
insert into sale_log values(1101, 4 , 'sales_mon', 100);
insert into sale_log values(1101, 4 , 'sales_tue', 150);
insert into sale_log values(1101, 4 , 'sales_wed', 80);
insert into sale_log values(1101, 4 , 'sales_thu', 60);
insert into sale_log values(1101, 4 , 'sales_fri', 120);
insert into sale_log values(1102, 5 , 'sales_mon', 300);
insert into sale_log values(1102, 5 , 'sales_tue', 300);
insert into sale_log values(1102, 5 , 'sales_wed', 230);
insert into sale_log values(1102, 5 , 'sales_thu', 120);
insert into sale_log values(1102, 5 , 'sales_fri', 150);
commit;
select * from sale_log;
SELECT col1, col2, ...var_col1, ... var_coln
FROM tables
PIVOT
(
aggregate_function(value_column)
FOR variable_column
IN(expr1 [[AS] var_col1], ... , expr_n [[AS] var_coln])
)
WHERE conditions
ORDER BY expression [ASC | DESC];
select * from sale_log
pivot(
sum(quantity)
for week_day in(
'sales_mon' as sales_mon,
'sales_tue' as sales_tue,
'sales_wed' as sales_wed,
'sales_thu' as sales_thu,
'sales_fri' as sales_fri
)
)
order by employee_id, week_id;
3. UNPIVOT
SELECT col1, ... , variable_column, value_column
FROM tables
UNPIVOT(
value_column
FOR variable_column
IN(expr1, expr2, ..., expr_n)
)
WHERE conditions
ORDER BY expression [ASC | DESC];
select employee_id, week_id, week_day, quantity
from sales
unpivot
(
quantity
for week_day
in(sales_mon, sales_tue, sales_wed, sales_thu, sales_fri)
);
select avg(salary),sum(salary),min(salary),max(salary)
from employees
where job_id like 'SA%';
select min(hire_date), max(hire_date)
from employees;
-- 날짜로 min,max가능
select min(first_name), max(last_name)
from employees;
select max(salary)
from employees;
2. COUNT
count(*)
count(expr)
select count(*) from employees;
select count(commission_pct) from employees;
3. STDDEV, VARIANCE
select sum(salary) as 합계,
round(avg(salary),2) as 평균,
round(stddev(salary),2) as 표준편차,
round(variance(salary),2) as 분산
from employees;
4. 그룹 함수와 NULL 값
- count(*)를 제외한 모든 그룹 함수는 열에 있는 NULL값을 연산에서 제외
select
round(sum(salary*commission_pct),2) as sum_bonus,
count(*) count,
round(avg(salary*commission_pct),2) as avg_bonus1,
round(sum(salary*commission_pct)/count(*),2) as avg_bonus2
from employees;
select avg(nvl(salary*commission_pct,0))
from employees;
GROUP BY
SELECT column, group_function(column)
FROM table
[WHERE condition(S)]
[GROUP BY group_by_expression]
[ORDER BY {column | expr[[ASC]|DESC],...};
1. GROUP BY 사용
select department_id, avg(salary)
from employees
group by department_id;
2. 하나 이상의 열로 그룹화
select department_id, job_id, sum(salary)
from employees
group by department_id, job_id;
3. 그룹 함수를 잘못 사용한 질의
- select 절의 그룹 함수가 아닌 모든 열이나 표현식은 group by 절에 있어야 한다.
- where 절을 사용해 그룹을 제한할 수 없다. having 사용
HAVING
- 그룹 제한하기 위해 사용
SELECT coulmn, group_function(column)
FROM table
[WHERE condition(s)]
[GROUP BY group_by_expression]
[HAVING group_condition]
[ORDER BY {column|expr[[ASC]|DESC]]}];
1. HAVING 사용
select department_id, avg(salary)
from employees
group by department_id
having avg(salary) > 2000;
select job_id, avg(salary) payroll
from employees
where job_id not like 'SA%'
group by job_id
having avg(salary) > 8000
order by avg(salary) desc;
GROUPING SETS
SELECT coulmn, group_function(column)
FROM table
[WHERE condition(s)]
[GROUP BY [GROUPING SETS] (group_by_expression)]
[HAVING group_condition]
[ORDER BY {column|expr[[ASC]|DESC]]}];
select department_id, job_id, round(avg(salary),2)
from employees
group by grouping sets(department_id, job_id)
order by department_id, job_id;
select department_id, job_id, manager_id, round(avg(salary),2) as avg_Sal
from employees
group by grouping sets((department_id, job_id),
(job_id, manager_id))
order by department_id, job_id, manager_id;
ROLLUP, CUBE
1. ROLLUP, CUBE사용
select department_id,job_id, round(Avg(salary),2), count(*)
from employees
group by department_id, job_id
order by department_id, job_id;
--각 부서의 직업별 평균만 알 수 있다.
--각 부서의 전체 평균을 알고싶다면 rollup사용
select department_id,job_id, round(Avg(salary),2), count(*)
from employees
group by rollup(department_id, job_id)
order by department_id, job_id;
- 여기에 직무별 평균과 사원의 수도 출력하고 싶으면 cube 사용
select department_id,job_id, round(Avg(salary),2), count(*)
from employees
group by cube(department_id, job_id)
order by department_id, job_id;
GROUPING
- ROLLUP, CUBE, GROUPING SETS 등 GROUP BY 확장 연산으로 소계의 일부로 생성된 null값일 경우 1을 반환
- 저장된 null값이거나 다른 값일 경우 0 반환
select
decode(grouping(department_id), 1, '소계',
to_Char(department_id)) as 부서,
decode(grouping(job_id),1,'소계',job_id) as 직무,
round(avg(salary),2) as 평균,
count(*) as 사원의수
from employees
group by cube(department_id, job_id)
order by 부서, 직무;
GROUPING_ID
- GROUPING_ID는 행과 연관된 GROUPING 비트 벡터에 해당하는 숫자를 반환
- GROUPING_ID를 사용하면 그룹화 수준 식별 가능
GROUPING_ID(column, column2,...)
select
decode(grouping_id(department_id, job_id),
2, '소계', 3, '합계',
to_char(department_id)) as 부서번호,
decode(grouping_id(department_id, job_id),
1,'소계',3,'합계',
job_id) as 직무,
grouping_id(department_id, job_id) as gid,
round(avg(salary),2) as 평균,
count(*) as 사원수
from employees
group by cube(department_id, job_id)
order by 부서번호, 직무;
select employee_id, first_name, hire_date
from employees
where hire_date='03/06/17';
--char가 DATE형으로 변환
select employee_id, first_name, department_id
from employees
where department_id='40';
--char가 NUMBER타입으로 자동 형 변환
2. 명시적 형 변환
변환 함수
설명
TO_CHAR(number [, 'fmt'])
숫자를 문자 타입으로
TO_CHAR(date[, 'fmt'])
날짜를 문자 타입으로
TO_NUMBER(char[, 'fmt'])
숫자를 포함하 문자를 숫자로
TO_DATE(char[, 'fmt'])
날짜를 나타내는 문자를 DATE타입으로
3. 날짜를 문자로 변환
TO_CHAR(date, 'fmt')
select first_name, TO_CHAR(hire_date, 'MM/YY') as hiremonth
from employees
where first_name='Steven';
select first_name, to_char(hire_date, 'YYYY"년" MM"월" DD"일"') as hiredate
from employees;
select first_name,to_char(hire_date, 'fmDdspth "of" Month YYYY fmHH:MI:SS AM',
'NLS_DATE_LANGUAGE=english') as hiredate from employees;
4. 숫자를 문자로 변환
TO_CHAR(number, 'fmt')
select first_name, last_name,to_char(salary, '$999,999') salary
from employees;
select first_name, last_name, salary*0.123456 salary1,
to_char(salary*0.123456, '$999,999.99') salary2
from employees
where first_name='David';
5. TO_NUMBER 함수
TO_NUMBER(char, 'fmt')
select '$5,500'-4000 from dual; --오류
select to_number('$5,500', '$999,999')-4000 from dual;
6. TO_DATE 함수
TO_DATE(char, 'fmt')
select first_name, hire_date
from employees
where hire_date=to_date('2003/06/17','YYYY/MM/DD');
select first_name, hire_date
from employees
where hire_date = to_date('2003년06월17일', 'YYYY"년"MM"월"DD"일"');
7. Null 치환 함수 NVL, NVL2, COALESCE
1) NVL1
NVL(expr1, expr2)
--expr1:널이 있을 수 있는 열
--expr2:널일경우 치환할 값
select first_name, salary + salary*nvl(commission_pct,0) from employees;
2) NVL2
nvl2(expr1, expr2, expr3)
select first_name,
nvl2(commission_pct, salary+salary*commission_pct, salary) as nann_sal
from employees;
3) COALESCE
COALESCE(expr1, ...)
select first_name,
coalesce(salary+salary*commission_pct, salary)as ann_sal
from employees;
8. 기타 변환 함수
1) LNNVL
LNNVL(expr1)
select first_name, coalesce(salary*commission_pct,0) as bonus from employees
where salary*commission_pct < 650;
==>null인 것들을 모두 제외하게 됨
select first_name, coalesce(salary*commission_pct,0) as bonus from employees
where lnnvl(salary*commission_pct >= 650);
=>null값도 포함시킴
2) DECODE
select job_id, salary,
decode(job_id, 'IT_PROG', salary*1.10,
'FI_MGR', salary*1.15,
'FI_ACCOUNT', salary*1.20,
salary) as revised_sal
from employees;
3) CASE
select job_id, salary,
case job_id when 'IT_PROG' then salary*1.10
when 'FI_MGR' then salary*1.15
when 'FI_ACCOUNT' then salary*1.20
else salary
end as revise_sal
from employees;
=>위와 같은 결과
select employee_id, salary,
case when salary < 5000 then salary*1.2
when salary < 10000 then salary*1.10
when salary < 15000 then salary*1.05
else salary
end as revised_sal
from employees;
집합 연산자
1. UNION
- 합집합과 같은 의미
- 중복된 정보는 한 번만 보여줌.
select employee_id, first_name from employees where hire_date like '04%'
union
select employee_id, first_name from employees where department_id=20;
2. UNION ALL
- 중복된 정보 포함
select employee_id, first_name from employees where hire_date like '04%'
union all
select employee_id, first_name from employees where department_id=20;
3. INTERSECT
- 중복된 행만 출력
- 교집합과 같은 의미
select employee_id, first_name from employees where hire_date like '04%'
intersect
select employee_id, first_name from employees where department_id=20;
4. MINUS
- 첫번째 쿼리에만 포함되고 두번째 쿼리에는 없는 데이터를 보여준다.
- 차집합과 같은 의미
select employee_id, first_name from employees where hire_date like '04%'
minus
select employee_id, first_name from employees where department_id=20;
select last_name, lower(last_name), initcap(last_name), upper(last_name)
from employees;
select last_name, lower(last_name), initcap(last_name), upper(last_name)
from employees
where lower(last_name)='austin';
2. LENGTH, INSTR
select first_name, length(first_name),instr(first_name,'a')
from employees;
3. SUBSTR, CONCAT
select first_name, substr(first_name,1,3), concat(first_name, last_name)
from employees;
4. LPAD, RPAD
select rpad(first_name,10,'-') as name, lpad(salary,10,'*')as sal
from employees;
5. LTRIM, RTRIM
select ltrim('JavaSpecialist','Java') from dual;
select ltrim(' JavaSpecialist') from dual;
select trim( 'JavaSpecialist ') from dual;
6. REPLACE, TRANSLATE
select replace('JavaSpecialist','Java','BigData') from dual;
select replace('Java Specialist',' ','') from dual;
select translate('javaspecialist','abcdefghijklmnopqrstuvwxyz','defghijklmnopqrstuvwxyzabc') from dual;
7. 실전 문제
select rpad(substr(first_name,1,3),length(first_name),'*') as name,
lpad(salary,10,'*') as salary
from employees
where lower(job_id) = 'it_prog';
Create table test_regexp (col1 varchar2(10));
insert into test_regexp values('ABCDE01234');
insert into test_regexp values('01234ABCDE');
insert into test_regexp values('abcde01234');
insert into test_regexp values('01234abcde');
insert into test_regexp values('1-234-5678');
insert into test_regexp values('234-567890');
select * from test_regexp
where regexp_like(col1,'[0-9][a-z]');
select * from test_regexp
where regexp_like(col1,'[0-9]{3}-[0-9]{4}$');
select * from test_regexp
where regexp_like(col1,'[[:digit:]]{3}-[[:digit:]]{4}$');
select * from test_regexp
where regexp_like(col1,'^[0-9]{3}-[0-9]{4}');
create table qa_master (qa_no varchar(10));
alter table qa_master add constraint qa_no_chk check
(regexp_like(qa_no,
'^[[:alpha:]]{2}-[[:digit:]]{2}-[[:digit:]]{4}$'));
insert into qa_master values('QA-01-0001');
insert into qa_master values('00-01-0001'); --오류
insert into test_regexp values('@!=)(9&%$#');
insert into test_regexp values('자바3');
select col1,regexp_instr(col1,'[0-9]') as data1,
regexp_instr(col1,'%') as data2 from test_regexp;
SELECT [DISTINCT] {* | coulumn[[AS] alias], ...}
FROM tablename;
SELECT
하나 이상의 열을 나열합니다.
DISTINCT
중복 제거
*
모든 열 선택
column
명명된 열 선택
AS
열 별칭(alias) 지정
alias
선택된 열을 다른 이름으로 변경
FROM tablename;
열을 포함하는 테이블 명시
2. SQL 문장 작성
- 대/소문자 구별X
- 문장이 한 줄 이상일 수 있음
- 키워드는 단축하거나 줄을 나눠 쓸 수 있음
- 절은 대개 줄을 나누어 작성
- 탭과 들여쓰기는 가독성을 위해 사용
SQL> SELECT first_name, last_name, salary
2 FROM employees;
3. 모든 열 선택
SQL> SELECT *
2 FROM departments;
4. 특정 열 선택
SQL> SELECT department_name, location_id
2> FROM departments;
5. 기본 표시 형식
- 디폴트 데이터 자리맞춤을 지정합니다.
- 날짜와 문자 데이터는 왼쪽 정렬됩니다.
- 숫자 데이터는 오른쪽 정렬됩니다.
- 디폴트 열 헤딩은 대문자로 출력됩니다
6. 열 별칭(alias) 정의
- 열 헤딩 이름을 변경합니다.
- 계산할 때 유용
- 열 이름 바로 뒤에 두며 AS 별칭 으로 하기도 합니다.
- 공백/특수문자는 인용부호(" ")가 필요합니다.
SQL> SELECT first_name AS 이름, salary 급여
2 FROM employees;
7. 리터럴(literal) 문자 스트링과 연결 연산자
- SELECT 절에 포함된 리터럴은 문자 표현식 또는 숫자 입니다.
- 날짜와 문자 리터럴 값은 단일 인용부호(' ')안에 있어야 합니다.
- 숫자 리터럴은 단일 인용부호(' ')를 사용하지 않습니다.
- 각각의 문자스트링은 리턴된 각 행에 대한 결과입니다.
- ||를 이용하면 값을 연결해 줍니다
SQL> SELECT first_name || ' ' || last_name || '''s salary is $' || salary
2 AS "Employee Details"
3 FROM employees;
8. 중복 행과 DISTINCT
- 디폴트 출력은 중복되는 행을 포함하는 모든 행입니다.
- SELECT 절에서 DISTINCT 키워드를 사용하여 중복되는 행을 제거합니다.
데이저 제한
1. Selection
- 원하는 행을 선택적으로 조회하는 것
2. 선택된 행 제한
- WHERE 절을 사용하여 반환하는 행을 제한
- WHERE 절은 FROM절 다음에 위치
- WHERE 절은 열 이름, 비교 연산자, 비교할 열 이름 또는 값의 목록으로 구성
SELECT [DISTINCT] {*|coulumn[[AS] alis], ...}
FROM table
[WHERE condition(s)];
SELECT first_name, job_id, department_id
FROM employees
WHERE job_id = 'IT_PROG';
3. 문자와 날짜
- 문자, 문자열, 날짜는 ''로 둘러쌈.
- 문자 값은 대/소문자 구분, 날짜 값은 형식을 따른다.
- 기본 날짜 형식은 'DD-MON-YY'
SELECT first_name, hire_date
FROM employees
WHERE last_name='King';
4. 비교 연산자
연산자
설명
=
같다
>
크다
>=
크거나 같다
<
작다
<=
작거나 같다
<> , !=
같지 않다
5. BETWEEN 연산자
- 값의 범위에 해당하는 값을 출려하기 위해 BEETWEEN 사용
- 하한값 먼저 명시
- 하한값, 상한값 모두 포함
-- 2004년에 입사한 사원
SELECT first_name, salary, hire_date
FROM employees
WHERE hire_date BETWEEN '04/01/01' AND '04/12/31';
6. IN 연산자
- 목록에 값이 있는지 비교
SELECT employee_id, first_name, salary, manager_id
FROM employees
WHERE manager_id IN(101, 102, 103);
7. LIKE 연산자
- 검색 문자열에 대한 와일드카드 검색
- 검색 조건은 문자, 날짜 포함 가능
- %는 문자가 없거나 하나 이상 문자들 대신
- _는 하나의 문자 대신
--LIKE연산
SELECT first_name, last_name, job_id, department_id
FROM employees
WHERE job_id LIKE 'IT_%';
8. IS NULL 연산자
- IS NULL 연산자로 널인지 테스트
- 널이 아닌 값은 IS NOT NULL
SELECT first_name, manager_id
FROM employees
WHERE manager_id IS NULL;
9. 논리 연산자
- AND는 양쪽 조건이 참이어야 TRUE 반환
- OR은 한쪽의 조건이 참이면 TRUE 반환
- NOT 연산자는 뒤의 조건에 반대되는 결과 반환
10. 논리 연산자 우선순위
우선순위
연산자
1
모든 비교 연산자
2
NOT
3
AND
4
OR
데이터 정렬
- 질의에 의해 검색되는 행을 정렬할 수 있다.
- ORDER BY 절은 SELECT 문장의 가장 뒤에 옴.
- ASC :오름차순
- DSEK : 내림차순
SELECT expr
FROM table
[WEHRE condition(s)]
[ORDER BY {coluumn|expr [[ASC]|DESC];
select first_name, hire_date
from employees
order by hire_date;
select first_name, hire_date from employees
order by hire_date desc;
select first_name, salary*12 as annsal
from employees
order by annsal;
select first_name, salary*12 as annsal
from employees
order by 2;
실습
1. 모든 사원의 사원번호, 이름, 입사일, 급여를 출력하세요.
2. 모든 사원의 이름과 성을 붙여 출력하세요. 열 별칭은 name으로 하세요.
3. 50번 부서 사원의 모든 정보를 출력하세요.
4. 50번 부서 사원의 이름, 부서번호, 직무아이디를 출력하세요.
5. 모든 사원의 이름, 급여 그리고 300달러 인상된 급여를 출력하세요.
6. 급여가 10000보다 큰 사원의 이름과 급여를 출력하세요.
7. 보너스를 받는 사원의 이름과 직무, 보너스율을 출력하세요.
8. 2003년도 입사한 사원의 이름과 입사일 그리고 급여를 출력하세요.(BETWEEN 연산자 사용)
9. 2003년도 입사한 사원의 이름과 입사일 그리고 급여를 출력하세요.(LIKE 연산자 사용)
10. 모든 사원의 이름과 급여를 급여가 많은 사원부터 적은 사원순서로 출력하세요.
11. 위 질의를 60번 부서의 사원에 대해서만 질의하세요.
12. 직무아이디가 IT_PROG 이거나, SA_MAN인 사원의 이름과 직무아이디를 출력하세요.
13. Steven King 사원의 정보를 “Steven King 사원의 급여는 24000달러 입니다” 형식으로 출력하세요.
14. 매니저(MAN) 직무에 해당하는 사원의 이름과 직무아이디를 출력하세요.
15. 매니저(MAN) 직무에 해당하는 사원의 이름과 직무아이디를 직무아이디 순서대로 출력하세요
--연습문제
---1
select employee_id, first_name, hire_date, salary
from employees;
--2
select first_name ||' '|| last_name as name
from employees;
--3
select * from employees where department_id=50;
--4
select first_name, department_id, job_id from employees where department_id=50;
--5
select first_name, department_id, salary, salary+300 from employees;
--6
select first_name, salary from employees where salary>10000;
--7
select first_name, job_id, commission_pct from employees
where commission_pct is not null;
--8
select first_name, hire_date,salary from employees
where hire_date between '03/01/01' and '03/12/31';
--9
select first_name,hire_date, salary
from employees
where hire_date like '03%';
--10
select first_name, salary from employees
order by salary desc;
--11
select first_name, salary from employees
where department_id=60
order by salary desc;
--12
select first_name, job_id
from employees
where job_id in('IT_PROG', 'SA_MAN');
--13
select first_name||' '||last_name||' 사원의 급여는 '||salary||'달러입니다.'
from employees
where last_name='King' and first_name='Steven';
--14
select first_name, job_id from employees
where job_id like '%MAN';
--15
select first_name, job_id from employees
where job_id like '%MAN'
order by job_id;
- ACID 규정 준수 : 데이터베이스 트랜잭션이 안전하게 수행된다는 것을 보장하기 위한 성질을 가리키는 용어
원자성(Atomicity)
일관성(Consistency)
독립성(Isolation)
지속성(Durability)
- 트랜잭션과 관련된 작업들이 부분적으로 실행되다가 중단되지 않는 것을 보장하는 능력이다. - 예를 들어, 자금 이체는 성공할 수도 실패할 수도 있지만 보내는 쪽에서 돈을 빼 오는 작업만 성공하고 받는 쪽에 돈을 넣는 작업을 실패해서는 안된다. - 원자성은 이와 같이 중간 단계까지 실행되고 실패하는 일이 없도록 하는 것이다.
- 트랜잭션이 실행을 성공적으로 완료하면 언제나 일관성 있는 데이터베이스 상태로 유지하는 것을 의미한다. - 무결성 제약이 모든 계좌는 잔고가 있어야 한다면 이를 위반하는 트랜잭션은 중단된다.
- 트랜잭션을 수행 시 다른 트랜잭션의 연산 작업이 끼어들지 못하도록 보장하는 것 - 트랜잭션 밖에 있는 어떤 연산도 중간 단계의 데이터를 볼 수 없음을 의미한다. - 은행 관리자는 이체 작업을 하는 도중에 쿼리를 실행하더라도 특정 계좌간 이체하는 양 쪽을 볼 수 없다.
- 성공적으로 수행된 트랜잭션은 영원히 반영되어야 함을 의미한다. - 시스템 문제, DB 일관성 체크 등을 하더라도 유지되어야 함을 의미한다. - 전형적으로 모든 트랜잭션은 로그로 남고 시스템 장애 발생 전 상태로 되돌릴 수 있다. - 트랜잭션은 로그에 모든 것이 저장된 후에만 commit 상태로 간주될 수 있다.
SQL> conn sys /as sysdba
Enter password:
Connected.
SQL> alter session set "_ORACLE_SCRIPT"=true;
Session altered.
SQL> @?/demo/schema/human_resources/hr_main.sql
specify password for HR as parameter 1:
1의 값을 입력하십시오: hr
specify default tablespeace for HR as parameter 2:
2의 값을 입력하십시오: users
specify temporary tablespace for HR as parameter 3:
3의 값을 입력하십시오: temp
specify log path as parameter 4:
4의 값을 입력하십시오: $ORACLE_HOME/demo/schema/log/
package miniprj.model;
import java.util.ArrayList;
public interface IBookDAO {
public int deleteBook(String name, String password);
public int insertBook(Book book);
public int updateBook(Book book);
public int getBookCount();
public Book getOne(String name, String password);
public ArrayList<Book> getAllBooks();
}